
譜聚類

譜聚類(英文:Spectral clustering)係一種聚類分析方法,要聚類嘅對象着視為一幅圖啲綟,啲對象之間嘅距離或者嘸相似度係着表示成圖啲綟之間啲加有權嘅檠。譜聚類係基於圖論對於個拉氏矩陣嘅分析結果,個拉氏矩陣對應返啲圖係有隻連通元件。由於矩陣啲特徵值亦都喊做頻譜,所以種方法喊做譜聚類。譜聚類嘅圖論理論基礎係由 Donath & Hoffman (1973) 同 Fiedler (1973) 奠定嘅。[1][2]

數學基礎
[編輯]圖縮減
[編輯]喺第一步,個圖着縮減,而個目的係從圖裏便鏟走所有啲權重(象徵距離)太大嘅檠。以下係啲方法:
ε鄰舍圖
[編輯]- 若果某檠嘅權重大過,就由圖度鏟走條檠。

k-nn 圖
[編輯]- 喺 k-nn 圖(最近鄰舍圖)裏便,一粒綟啲所有檠都根據檠嘅權重排序。有檠個權重大過第個最細權重嘅(象徵遠過第個鄰舍),就着從圖度鏟走。個 -nn 係嘸對稱嘅,即隻檠權重可能對於嚟講係細過第個最細檠權重,之對於又嘸細過佢個第個最細檠權重。得喊做係 k-nn 圖只需要到條檠保留喺圖裏便嘅,對於或者其中至少一個對象,個細過佢第個最細檠權重,即係每個對象至少有條檠。相反,一個「 佮埋嘅 k-nn 圖」只包含有啲檠、啲對於兩個對象都有細過個最細檠權重嘅,即係每個對象都最多有條檠。



全連接圖
[編輯]- 藉助相似度函數,檠權重係根據對象之間啲距離計出。相似度函數嘅一個例係高斯相似度函數。參數控制鄰舍大細似上高個參數或者噉。


-
 二維空間裏便8個對象嘅位置。
二維空間裏便8個對象嘅位置。 -
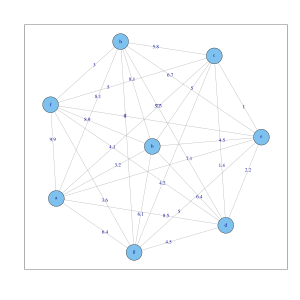 全連接圖,有啲帶歐氏距離嘅檠褦住8個對象。
全連接圖,有啲帶歐氏距離嘅檠褦住8個對象。 -
 8個對象啲歐氏距離嘅距離矩陣。
8個對象啲歐氏距離嘅距離矩陣。 -
 鄰舍圖( ) 為8個對象。
鄰舍圖( ) 為8個對象。 -
 8個對象個k-nn 圖() 。每粒綟至少有兩條檠。
8個對象個k-nn 圖() 。每粒綟至少有兩條檠。 -
 8個對象個普通 k-nn圖( )。每粒綟最多有兩條檠。數據集着分成三隻連通元件。
8個對象個普通 k-nn圖( )。每粒綟最多有兩條檠。數據集着分成三隻連通元件。 -
 拉氏矩陣,對於8個對象個普通 k-nn 圖() 嘅。
拉氏矩陣,對於8個對象個普通 k-nn 圖() 嘅。 -
 全連接圖,有返啲檠有高斯相似度函數值(),表示到8個對象。
全連接圖,有返啲檠有高斯相似度函數值(),表示到8個對象。












拉氏矩陣
[編輯]透過檠權重可以幫個對象整出(加權)鄰接矩陣。次數矩陣入便,對角線上包含有通向綟啲檠嘅權重總和(喺圖縮減之後)。係噉計得出三種拉氏矩陣:



- 非歸一化矩陣 ,
- 歸一化矩陣
- 歸一化矩陣 .



對於所有啲向量有:


由於拉氏矩陣係對稱同埋半正定嘅,所有特徵值都係實值而且大於或者等於零。對於拉氏矩陣,可以證明至少有一個特徵值係零。若果個圖由隻連通元件整出,係噉拉氏矩陣就係一個壆矩陣(Block矩陣,見上高幅圖同埋矩陣)。每一壆都有一個等於零嘅特徵值。對於特徵值係零嘅特徵向量必須有。因爲所有啲檠權重係正嘅,一隻連通元件啲綟所有都必須相同(所以有)。對於都有類似分析,唯有係特徵向量入便啲欄係由加權,而對於特徵向量啲欄係等於1。





對於聚類,分析拉氏矩陣啲最細特徵值同埋特徵向量。
-
 普通k-nn圖個拉普拉斯矩陣啲特徵值( ),對於個8個對象嘅數據。由於該圖由三隻連通元件組成,所以存在有三個值為0嘅特徵值。
普通k-nn圖個拉普拉斯矩陣啲特徵值( ),對於個8個對象嘅數據。由於該圖由三隻連通元件組成,所以存在有三個值為0嘅特徵值。 -
 三枚特徵向量啲值、拉氏矩陣啲特徵值係零嘅。啲欄應該等於 1,但個軟件重新調整過啲特徵向量,令佢哋長度係 1(即表中分別係、、,等啲特徵向量自點乘會得出1)。
三枚特徵向量啲值、拉氏矩陣啲特徵值係零嘅。啲欄應該等於 1,但個軟件重新調整過啲特徵向量,令佢哋長度係 1(即表中分別係、、,等啲特徵向量自點乘會得出1)。 -
 3D 散點圖畀特徵值零嘅三枚特徵向量嘅。8個對象着重疊畫喺三笪埞(overplotting),等 k平均聚類可以完美噉搵得到三隻連通元件。
3D 散點圖畀特徵值零嘅三枚特徵向量嘅。8個對象着重疊畫喺三笪埞(overplotting),等 k平均聚類可以完美噉搵得到三隻連通元件。







演算法
[編輯]各式演算法
[編輯]嘸同嘅譜聚類演算法有着開發出嚟:
非歸一化譜聚類:
- 計非歸一化嘅拉氏矩陣
- 計前枚特徵向量(係有最細特徵值嘅)
- 攞枚特徵向量啲行並用分匹方法整聚類,譬如k-平均演算法

Shi佮Malik嘅歸一化譜聚類:[4]
- 計歸一化嘅拉氏矩陣
- 計前特徵向量(係有最細特徵值嘅)
- 攞枚特徵向量啲行並用分匹方法整聚類
Ng、Jordan佮Weiss嘅歸一化譜聚類 :[5]
- 計歸一化嘅拉氏矩陣
- 計前特徵向量(係有最細特徵值嘅)
- 攞枚特徵向量啲行並用分匹方法整聚類
參數揀選
[編輯]關於過程參數同演算法嘅揀選,Ulrike von Luxburg個教程推薦係: [6]
- 鄰舍圖嘅揀選:k-nn 圖,因為識別嘸同密度嘅聚類識別得好啲並生成得稀疏拉氏矩陣。亦都可以喺大啲嘅域內變化,而同時嘸會改變到個聚類分析好多。
- 鄰舍圖啲參數嘅揀選:
- 對於k-nn 圖,係噉揀選嘅,即個圖啲連通元件嘸少過預期聚類裏便應有嘅。
- 對於普通 k-nn 圖,要大過k-nn度嘅,因爲普通k-nn 圖包含到嘅檠少過k-nn 圖。揀選嘅啟發式方法仲未知。
- 對於鄰舍圖應該揀係等於最長條檠喺最細生成樹(minimum spanning tree)度嘅。
- 對於啲全連接圖有高斯相似度函數嘅應該揀係令到結果幅圖對應返 k-nn 圖或者鄰舍圖。經驗法則仲有:等於最長條檠喺最細生成樹嘅或者作爲個平均距離去到隻最近鄰舍嘅,其中 .
- 聚類數嘅揀選:畫出拉氏矩陣啲特徵值,照大細排序並搵跳躍,譬如喺上高示意圖入便8對象數據集個第3同第4特徵值之間嘅。
- 拉氏矩陣嘅揀選:因爲對於嚟講,特徵向量入便啲欄係等於1,攞譬如k-means 演算法嚟聚類會幾好。

例
[編輯]Iris花數據集,係Sir Ronald Fisher爵士 (1936) 作爲判別分析嘅例使用到嘅。[7]有時,個數據集亦都着喊做「Anderson's Iris花數據集」,因為Edgar Anderson收集唨啲數據嚟量化Iris花嘅形態變化。[8]個數據集由 50 隻標本組成,每隻標本分為三隻物種:Iris setosa、Iris versicolor、Iris virginica。分別有測量到萼片同花瓣嘅長度同埋寬度,所以個數據集包含有150個觀察值同埋4個變量。



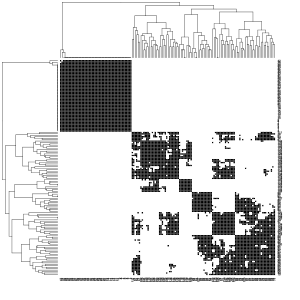
就好似喺散佈圖矩陣個左便(第一幅)圖形見到噉,三種類型之一(圖形中啲紅色)戥其他類型顯著嘸同。另外兩個物種互相之間好難分開。中間(第二幅)圖形顯示對象之間啲歐氏距離嘅灰度熱圖。灰色越深,對象離得越近。呢啲對象經已係噉重新排列法,即戥其他對象有相似距離嘅對象互相之間擺近。使用到嘅軟件用層次聚類嘅方法並顯示到個樹狀結構圖(Dendrogram)。右便(第三幅)圖形顯示到譜聚類嘅結果。可以睇得出,啲聚類戥三種類型有一定嘅一致性。
-
 黑色:啲對象之間嘅檠,喺 k-nn 圖( )度保有。白色:啲捱鏟走嘅檠。
黑色:啲對象之間嘅檠,喺 k-nn 圖( )度保有。白色:啲捱鏟走嘅檠。 -
 黑色:啲對象之間嘅檠,喺普通 k-nn 圖( )度保有。白色:啲捱鏟走嘅檠。
黑色:啲對象之間嘅檠,喺普通 k-nn 圖( )度保有。白色:啲捱鏟走嘅檠。 -
 散佈圖畀拉氏矩陣啲特徵值,對於k-nn 圖( )。
散佈圖畀拉氏矩陣啲特徵值,對於k-nn 圖( )。




左便兩幅圖像顯示到k-nn 圖或者普通 k-nn 圖裏便係邊啲檠着保留到(黑色)或者嘸着保留到(白色)。對於參數,最長檠首先係喺最細生成樹中着確定到,然之後幫所有觀察值計出對應嘅鄰舍數。平均值大概係 60 個鄰舍,係噉揀。之後計拉氏矩陣同埋矩陣啲特徵值。特徵值圖顯示到喺第二個或者第三個特徵值之後有好大跳躍。然之後對前三枚特徵向量進行3聚類嘅 k平均聚類。
| 種 | 聚類結果 | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| setosa | 0 | 0 | 50 |
| versicolor | 43 | 7 | 0 |
| virginica | 7 | 43 | 0 |
個混淆矩陣表明到譜聚類喺某種程度上重新發現過啲物種。譜聚類法完全正確噉分出Setosa聚類;喺 Versicolor同Virginica聚類嘅情況下有7 個觀測值各自捱錯誤噉分類到,對應嘅錯誤分類率係。

考
[編輯]- ↑ W. E. Donath, A. J. Hoffman: Lower bounds for the partitioning of graphs 互聯網檔案館嘅歸檔,歸檔日期2021年7月9號,.. In: IBM Journal of Research and Development. 17(5), (1973), S. 420–425.
- ↑ M. Fiedler: Algebraic connectivity of graphs. In: Czechoslovak Mathematical Journal. 23(2), (1973), S. 298–305.
- ↑ Ulrike von Luxburg (2007). "A Tutorial on Spectral Clustering" (PDF). 喺2018-01-06搵到. 互聯網檔案館嘅歸檔,歸檔日期2011-02-06. 〈存档副本〉 (PDF)。原著 (PDF)喺2011-02-06歸檔。喺2021-10-03搵到。
- ↑ J. Shi, J. Malik: Normalized cuts and image segmentation. In: IEEE Transactions on Pattern Analysis and Machine Intelligence. 22(8), (2000), S. 888–905. doi:10.1109/34.868688
- ↑ A. Y. Ng, M. I. Jordan, Y. Weiss: On spectral clustering: Analysis and an algorithm. In: Advances in Neural Information Processing Systems. 2, 2002, S. 849–856.
- ↑ Ulrike von Luxburg: A tutorial on spectral clustering. (PDF). In: Statistics and Computing. 17(4), (2007), S. 395–416. doi:10.1007/s11222-007-9033-z
- ↑ R. A. Fisher: The use of multiple measurements in taxonomic problems 互聯網檔案館嘅歸檔,歸檔日期2017年5月16號,.. In: Annals of Eugenics. 7(2), (1936), S. 179–188. doi:10.1111/j.1469-1809.1936.tb02137.x
- ↑ E. Anderson: The species problem in Iris. In: Annals of the Missouri Botanical Garden. 1936, S. 457–509.